It is generally recommended to model count outcomes (e.g., number of likes of social media posts) with Poisson models (or negative binomial models, but that’s for another simulation).
However, if we only want to compare two groups on a count outcome, Welch’s t-test might be an easier option and should also do well:
The mean is a consistent estimator of the rate parameter (CLT; see exercise 1a).
Welch’s t-test is robust if the group standard deviations are unequal, which, by definition, would be the case if the counted event occurred at different rates in the two groups.
Exercise 2a: False discovery rates
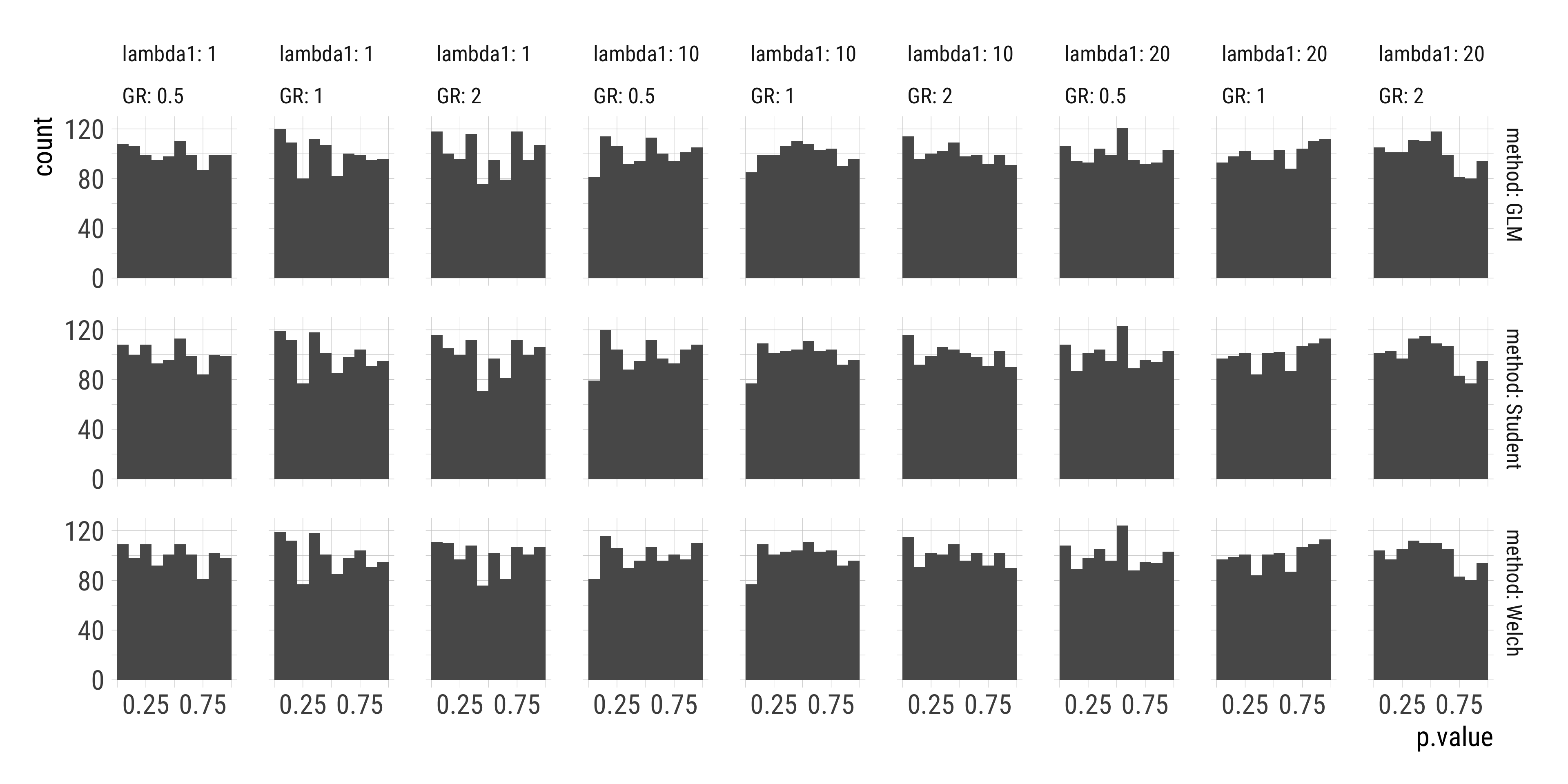
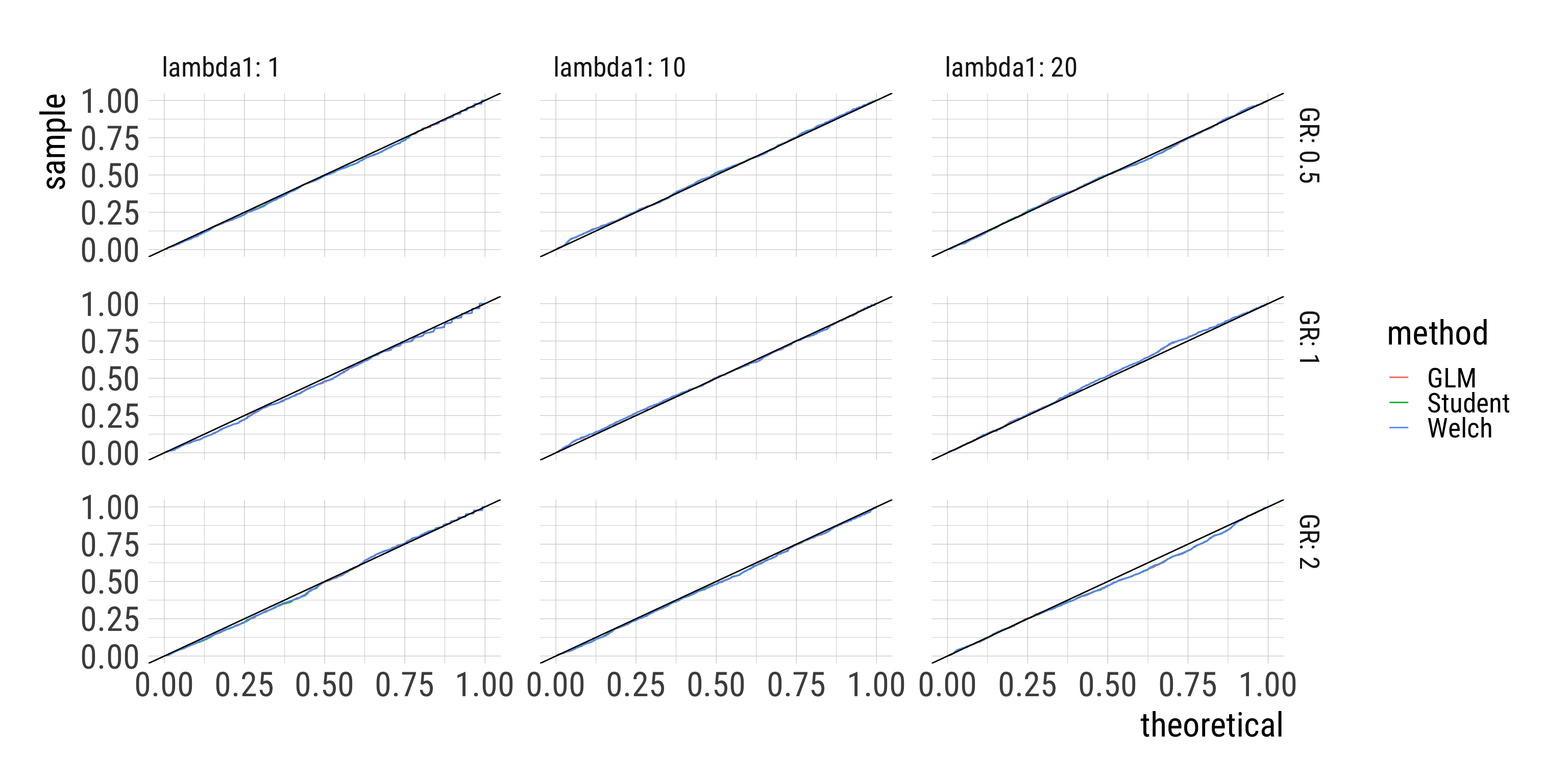
We can test this assumption by simulation, similar to the comparison of Student’s and Welch’s t-test. More specifically, we first want to compare the false discovery rates of
Student’s t-test,
Welch’s t-test, and
Poisson regression with a dummy predictor
if the true data generating process is drawing from a Poisson distribution.
Extend and adapt the previous simulation.
Simulation function
# No standard deviation ratio any more because SD fixed at sqrt(lambda)# M_diff not necessary at this stage, but useful latersim_ttest_glm =function(n =200, GR =1, lambda1 =1, M_diff =0) { n1 =round(n / (GR +1)) n2 =round(n1 * GR) lambda2 = lambda1 + M_diff g1 =rpois(n = n1, lambda = lambda1) g2 =rpois(n = n2, lambda = lambda2) Welch =t.test(g1, g2)$p.value Student =t.test(g1, g2, var.equal =TRUE)$p.value GLM =glm(outcome ~ group,data =data.frame(outcome =c(g1, g2),group =c(rep("g1", n1), rep("g2", n2))),family = poisson) res =lst(Welch, Student, GLM =coef(summary(GLM))[2, 4])return(res)}sim_ttest_glm()
# It makes sense to vary group size ratio and lambdaconditions =expand_grid(GR =c(0.5, 1, 2), n =600,lambda1 =c(1, 10, 20),M_diff =0) %>%rowid_to_column(var ="condition")conditions
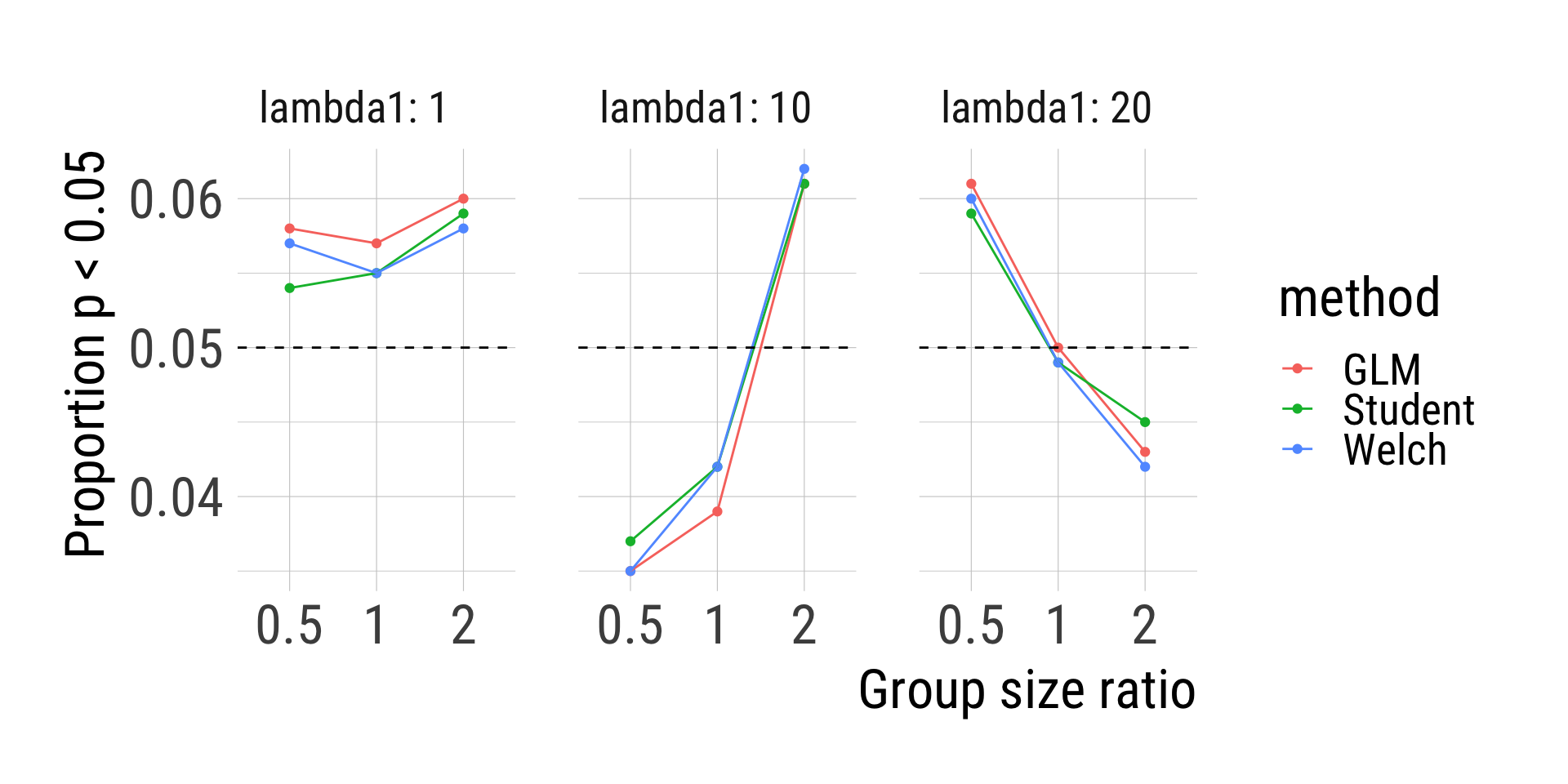
sims %>%group_by(GR, lambda1, method) %>%summarise(P_p05 =mean(p.value <0.05)) %>%ggplot(aes(factor(GR), P_p05, color = method, group = method)) +geom_point() +geom_line() +geom_hline(yintercept =0.05, linetype =2) +facet_wrap(vars(lambda1), labeller = label_both) +labs(x ="Group size ratio", y ="Proportion p < 0.05")
Summary
All tests performed very similarly in terms of false discovery rates.
Not surprising: Previous simulation study showed that Student’s t-test breaks if group sizes and group standard deviations are unequal. Group standard deviations were equal by definition of the data-generating process.
t-tests and Poisson regression did also very similarly.