Proof by simulation — The Central Limit Theorem (CLT)
Errors and power — Torturing the t-test
Misclassification and bias — Messages mismeasured
Outlook: What’s next?
4. Errors and power — Torturing the t-test
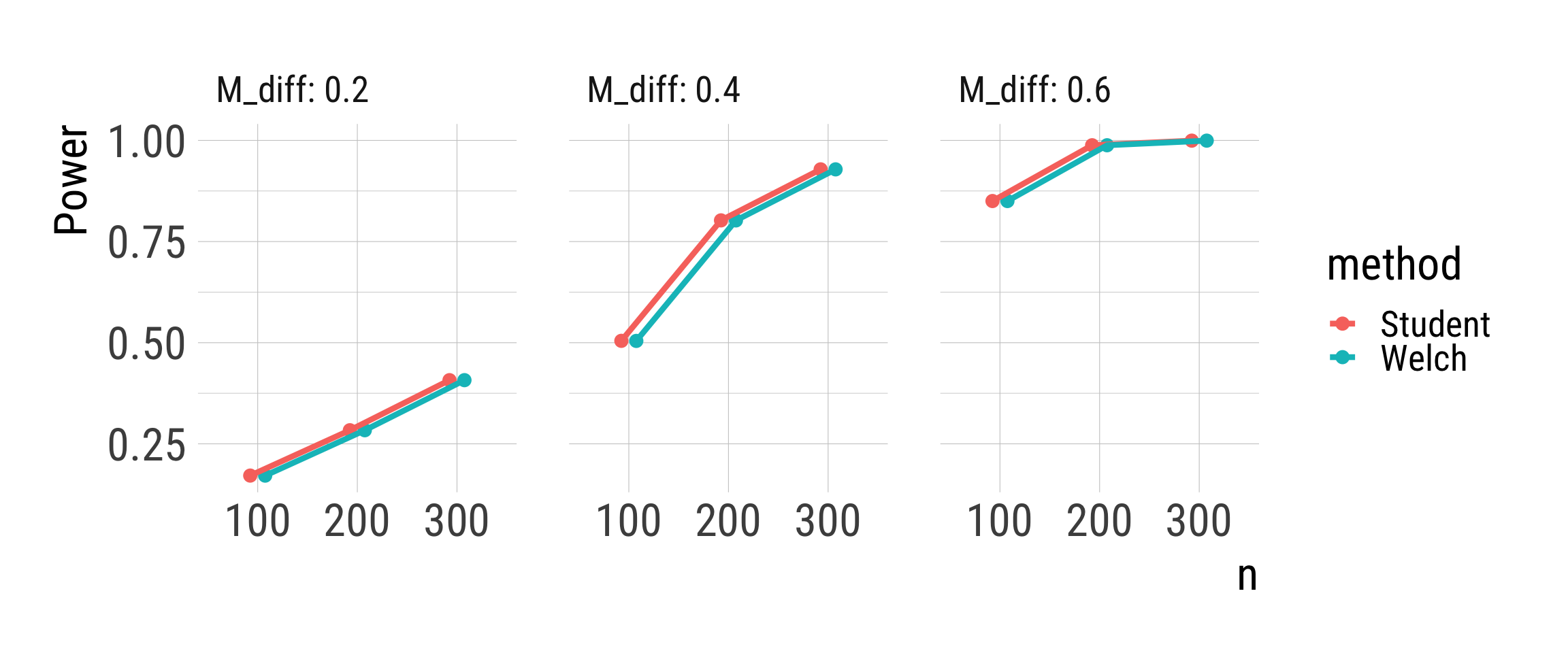
Comparison of Student’s and Welch’s t-tests
A priori power calculation for Welch’s t-test
Student’s t-test & Welch’s t-test
Old school advice: Student’s t-test for equal variances, Welch’s t-test for unequal variances.
Higher power of Student’s t-test if assumptions hold.
Modern advice: Always use Welch’s t-test.
Better if assumptions are violated; not worse if assumptions hold.
e.g., Delacre, M., Lakens, D., & Leys, C. (2017). Why Psychologists Should by Default Use Welch’s t-test Instead of Student’s t-test. International Review of Social Psychology, 30(1). https://doi.org/10.5334/irsp.82
For those who don’t care about t-tests: Idea also applies to heteroskedasticity-consistent standard errors.
Second Simulation study: Power
Question: What is the goal of the simulation?
Comparison of Student’s and Welch’s t-tests
Quantities of interest: What is measured in the simulation?
Power (\(1 - \beta\)) of the tests
Evaluation strategy: How are the quantities assessed?
Comparison of statistical power to reject the Null hypothesis if the alternative hypothesis is true
Conditions: Which characteristics of the data generating model will be varied?
Sample size, effect size (mean difference)
Data generating model: How are the data simulated?
Random draws from normal distributions with different group means and different overall sample sizes, but euqal group sizes and standard deviations
Additional practical considerations
How to adapt the simulation function to include different group means
How to adapt the experimental conditions
to include different group means and different total sample sizes
to include many different levels of the total sample size
Adapt the simulation function
Include new argument M_diff
Mean of the treatment condition; equals mean difference, as mean of the control is fixed at 0.
Mean difference equals standardized effect size d if SDR, and, consequently, both group standard deviations, are 1.
Two-sample t test power calculation
n = 50, 100, 150
delta = 0.4
sd = 1
sig.level = 0.05
power = 0.5081451, 0.8036466, 0.9322752
alternative = two.sided
NOTE: n is number in *each* group
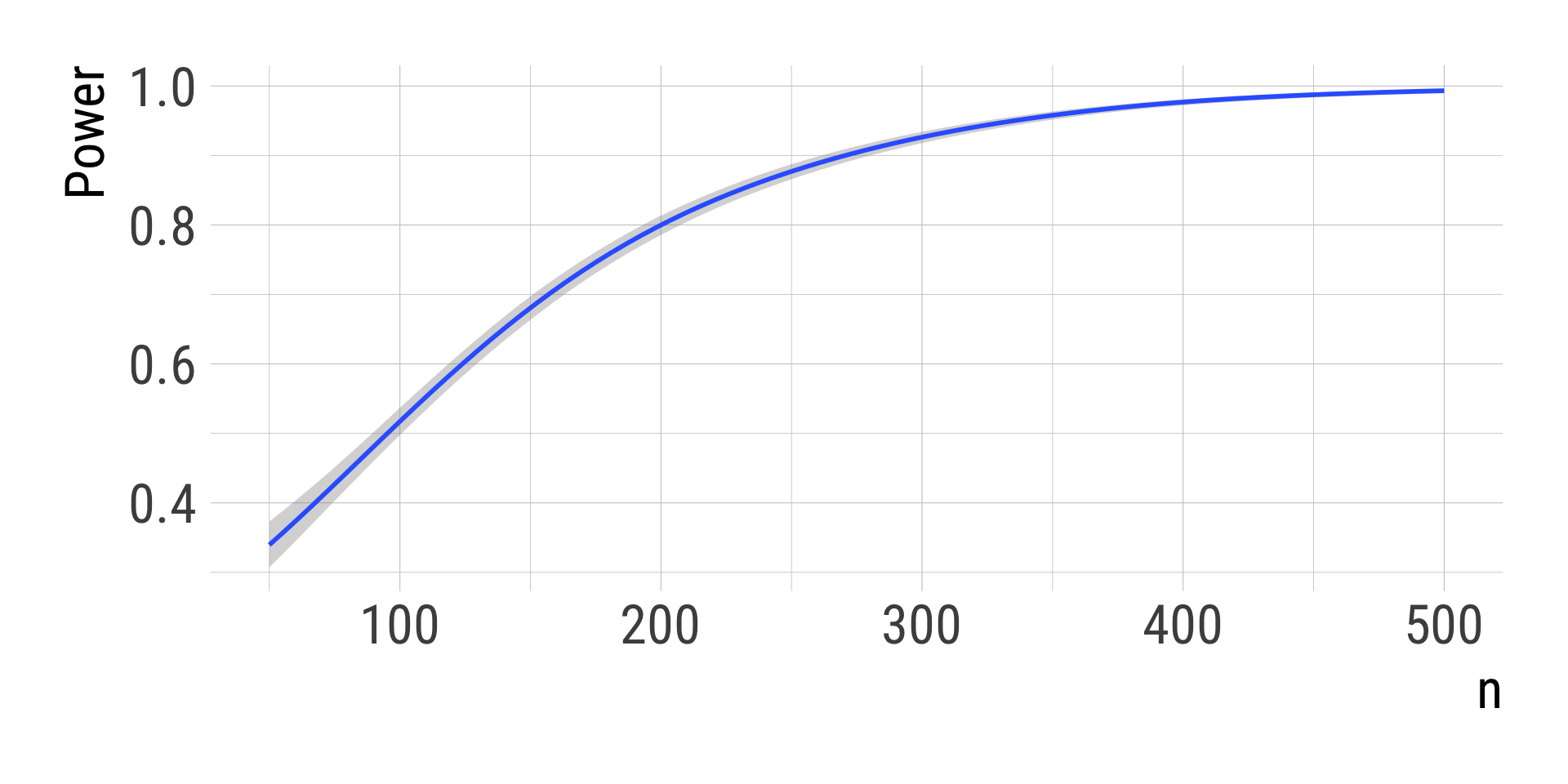
Option 2: many random draws of n from a distribution
i =250*46# same total number of simulationsset.seed(86)conditions =tibble(sim =1:i,GR =1, SDR =1,n =sample(x =50:500, size = i, replace =TRUE),M_diff =0.4)conditions
Two-sample t test power calculation
n = 60, 128, 202
delta = 0.4
sd = 1
sig.level = 0.05
power = 0.5843645, 0.8902603, 0.9798356
alternative = two.sided
NOTE: n is number in *each* group
Calculator: Summary
(Trivial) result: Larger sample size, more power
General take-away: Using many values instead of few discrete factor levels can be an interesting alternative
if we know (assume) that there is a fixed functional relationship with the outcome
if we want to look at an outcome across the whole range of values
if we want to make predictions across the range of values
if we evaluate models which need more computational resources
Not so helpful if discretized after the simulation.
Questions?
A priori power calculation for Welch’s t-test
Getting started: Some preliminary thoughts
We know that effect size and total sample size are positively related to statistical power, so we are not that interested in their effects.
We know less about the role of group sample sizes and group standard deviations differences, so this is what we want to investigate in the simulation.
We have to think more about how we define the effect size.
This is generally one of the harder tasks in a priori power calculation
and it becomes more complicated if simple “mean divided by SD” rules of thumb get more ambiguous.
Third Simulation study: Power (again)
Question: What is the goal of the simulation?
Understand roles of group sample sizes and group standard deviations for statistical power
Quantities of interest: What is measured in the simulation?
Power (\(1 - \beta\)) of the designs using Welch’s t-test
Evaluation strategy: How are the quantities assessed?
Comparison of statistical power to reject the Null hypothesis if the alternative hypothesis is true
Conditions: Which characteristics of the data generating model will be varied?
Group sample sizes, group standard deviations
Data generating model: How are the data simulated?
Random draws from normal distributions with different group sizes and standard deviations, but fixed group mean differences and overall sample size.
First try: Adapt the simulation function
We use the same simulation function as before.
sim_ttest =function(n =200, GR =1, SDR =1, M_diff =0) { n1 =round(n / (GR +1)) n2 =round(n1 * GR) sd1 =1 sd2 = sd1 * SDR # sd2/sd1 g1 =rnorm(n = n1, mean =0, sd = sd1) g2 =rnorm(n = n2, mean = M_diff, sd = sd2) res =t.test(g1, g2)$p.valuereturn(res)}sim_ttest(n =300, M_diff =0.3, GR =0.5)
[1] 0.1476812
First try: Adapt the experimental conditions
Total sample size n = 300 and effect size M_diff = 0.3 are now fixed.
If the SD ratio is not equal to 1, the pooled SD is not equal to 1 and the mean difference is not in units of the pooled SD (as in traditional d).
Instead, it is the difference in SD of the control group units.
Sensible definition for intervention trials with passive control group: Estimate of the population variation without a intervention.
Maybe less sensible in other designs with more active controls (e.g., typical media effects experimental studies) or im observational studies (e.g., gender differences in some outcome).
This has some implications
For substantive interpretation:
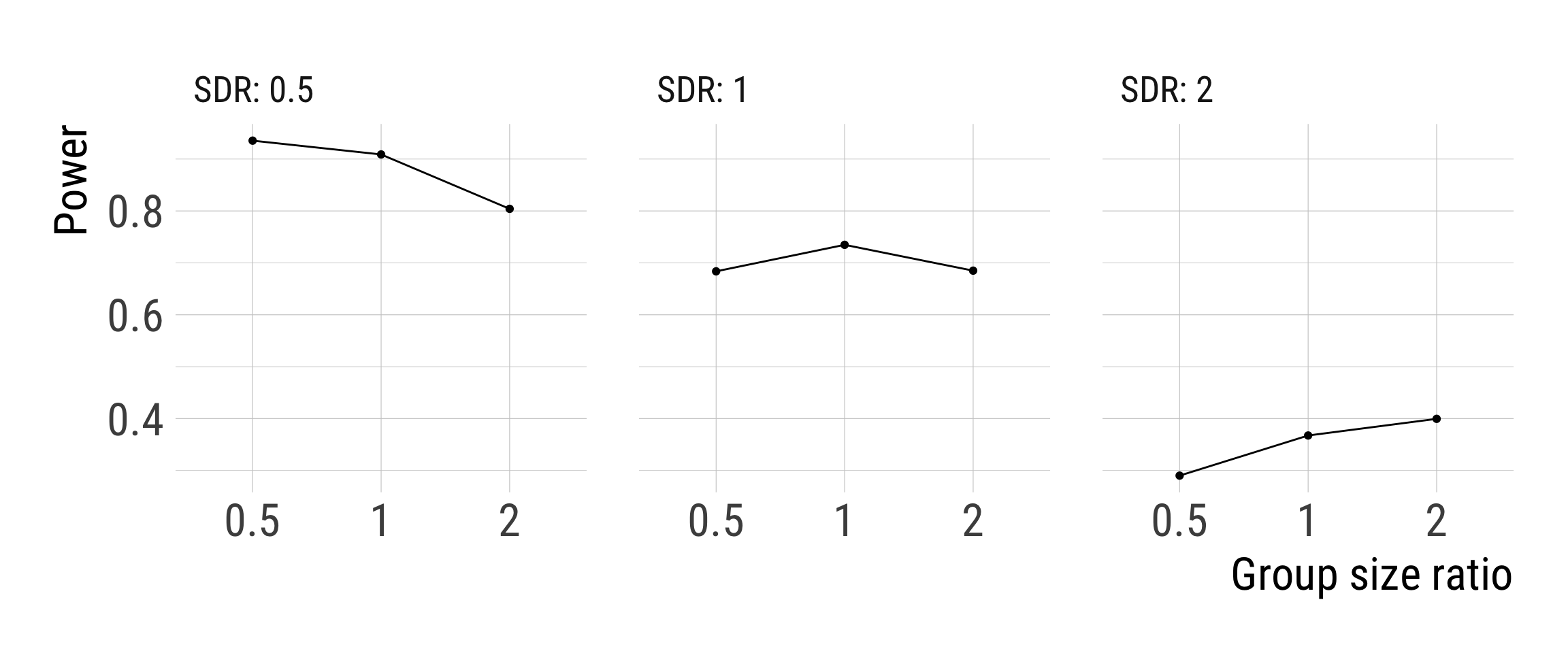
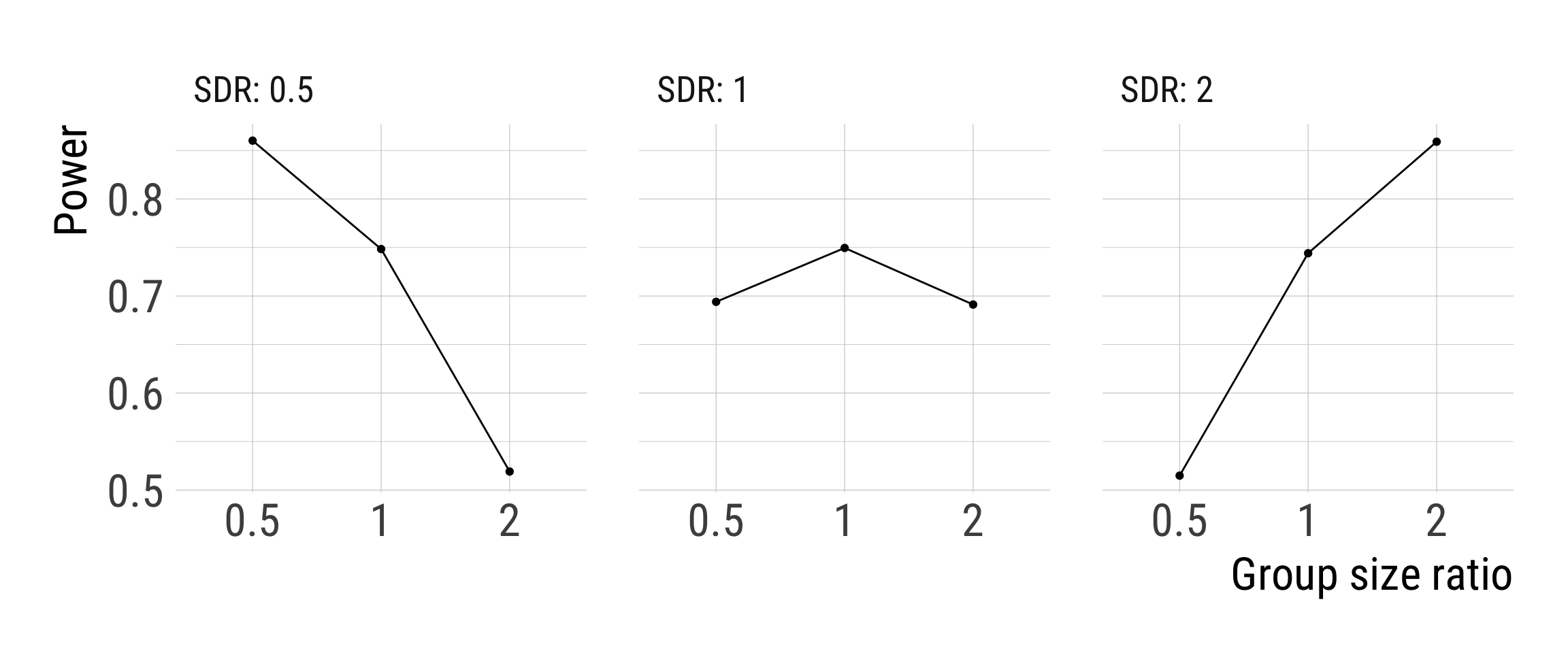
SDR = 0.5 assumes a treatment which not only increases the level of the outcome by M_diff, but also halves the variation in the outcome.
SDR = 2 assumes a treatment which not only increases the level of the outcome by M_diff, but also doubles the variation in the outcome.
Heterogeneous treatment effects!
First try: Run simulation experiment
set.seed(7913)i =10000tic()sims =map_dfr(1:i, ~ conditions) %>%# each condition 10,000 timesrowid_to_column(var ="sim") %>%rowwise() %>%mutate(p.value =sim_ttest(n = n, M_diff = M_diff, GR = GR, SDR = SDR))toc()
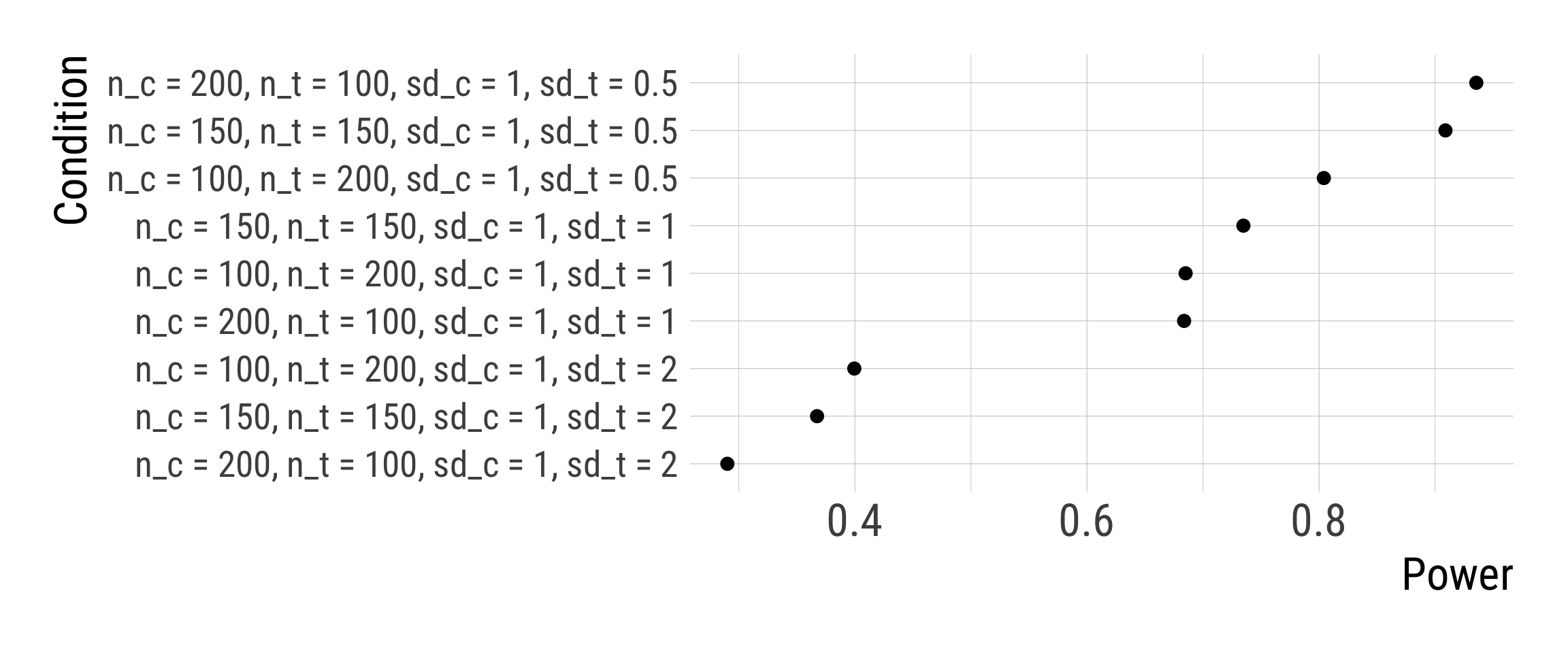
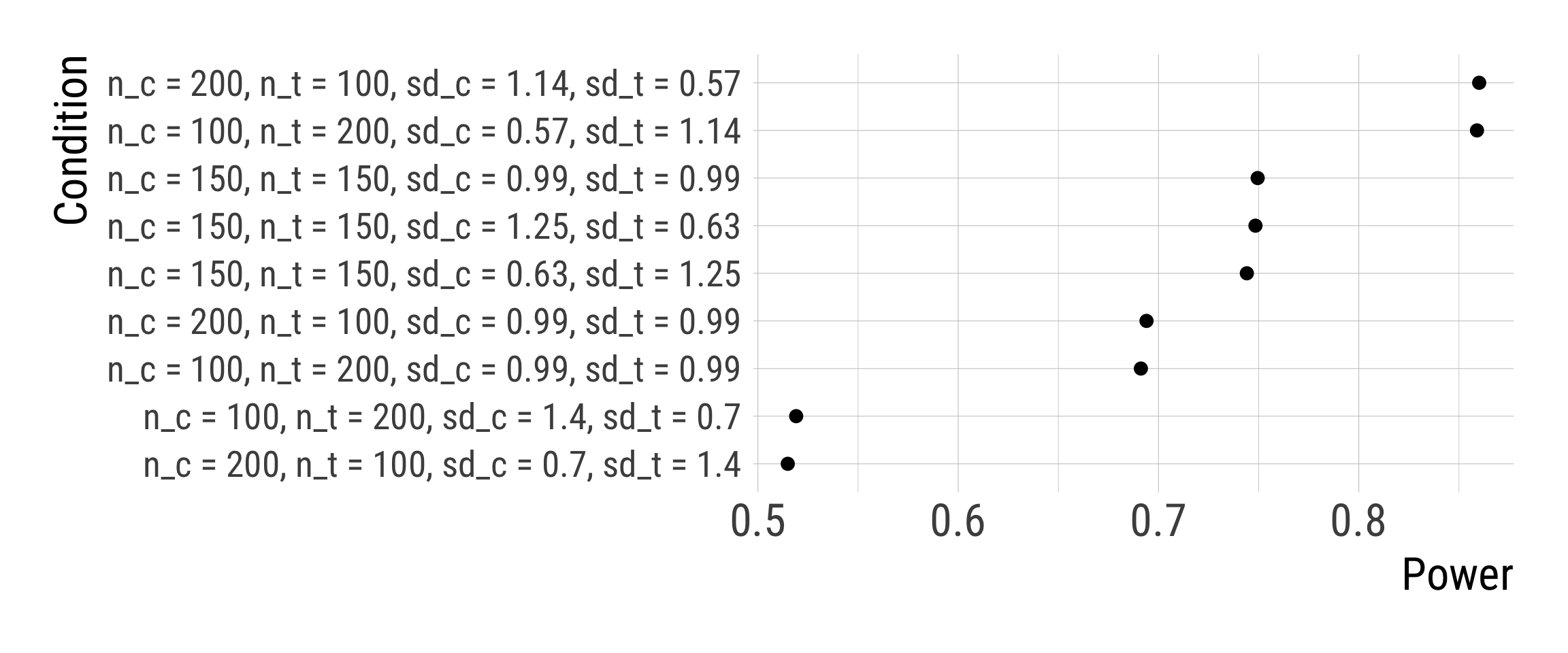
Fixing the pooled SD to 1 makes the patterns much clearer.
If we assume different group SDs, we should allocate more observations in the group with more variation.
If we assume similar group SDs, we should plan with similar group sample sizes.
For planing experimental designs, it is a decision under uncertainty about treatment effect heterogeneity.
Simulation for a priori power calculation
What’s the power? Don’t expect an easy answer!
Simulation is a very flexible and powerful approach to a priori power calculation. We can, in principle, test many different design features and statistical methods.
However, a meaningful power calculation (not only, but in particular with simulation methods) requires deep understanding of all involved components.
Implementing simulation methods for a priori power calculation from scratch is very revealing, because it makes it very obvious how much we need to know to arrive at a sensible answer.
Questions?
Group exercise 2
Exercise 2: Welch’s t-test for count data
Part 2: Power
We have shown in Part 1 of the exercise that the false discovery rates of t-tests and Poisson regression are similar even if the true data generating process is drawing from a Poisson distribution.
In Part 2, we want to compare the statistical power of the methods across a range of plausible scenarios.
Exercise 2b: Power
We want to compare the statistical power of
Welch’s t-test and
Poisson regression with a dummy predictor
if the true data generating process is drawing from Poisson distributions with different rate parameters.
If necessary: Adapt the simulation function from Exercise 2a.
Choose a sensible set of parameter combinations for the Monte Carlo experiment.
Exercise 2b: Help
Expand if you need help.
Don’t expand if you want to figure it out by yourself.
Scroll down if you need more help on later steps.
Simulation function adapted from Exercise 2a
Code
# We use almost the same simulation function, # but we omit Student's t-test, because we already showed its# problems with unequal group sizes and group SDssim_ttest_glm =function(n =200, GR =1, lambda1 =1, M_diff =0) { n1 =round(n / (GR +1)) n2 =round(n1 * GR) lambda2 = lambda1 + M_diff g1 =rpois(n = n1, lambda = lambda1) g2 =rpois(n = n2, lambda = lambda2) Welch =t.test(g1, g2)$p.value GLM =glm(outcome ~ group,data =data.frame(outcome =c(g1, g2),group =c(rep("g1", n1), rep("g2", n2))),family = poisson) res =lst(Welch, GLM =coef(summary(GLM))[2, 4])return(res)}
Conditions I: Simple variation of differences between rate parameters
Code
# It makes sense to vary group size ratio, lambda, and M_diff# The positive relationship between n and power is trivialconditions =expand_grid(GR =c(0.5, 1, 2), n =200,lambda1 =c(1, 10, 20),M_diff =c(0.3, 0.5, 0.8)) %>%rowid_to_column(var ="condition")
Conditions II: Variation of differences between rate parameters standardized by \(\sqrt{\lambda_1}\)
Code
conditions =expand_grid(GR =c(0.5, 1, 2), n =200,lambda1 =c(1, 10, 20),d =c(0.2, 0.4, 0.6)) %>%# standardized mean difference.mutate(M_diff = d *sqrt(lambda1)) %>%# absolute mean differencerowid_to_column(var ="condition")
Result plot: Power at \(p < .05\)
Code
sims %>%group_by(GR, lambda1, M_diff, method) %>%summarise(P_p05 =mean(p.value <0.05)) %>%ggplot(aes(factor(GR), P_p05, color = method, group = method)) +geom_point() +geom_line() +facet_grid(M_diff ~ lambda1, labeller = label_both) +labs(x ="Group size ratio", y ="Power")