We have shown in Part 1 of the exercise that the false discovery rates of t-tests and Poisson regression are similar even if the true data generating process is drawing from a Poisson distribution.
In Part 2, we want to compare the statistical power of the methods across a range of plausible scenarios.
Exercise 2b: Power
We want to compare the statistical power of
Welch’s t-test and
Poisson regression with a dummy predictor
if the true data generating process is drawing from Poisson distributions with different rate parameters.
If necessary: Adapt the simulation function from Exercise 2a.
Choose a sensible set of parameter combinations for the Monte Carlo experiment.
Simulation function
# We use almost the same simulation function, # but we omit Student's t-test, because we already showed its# problems with unequal group sizes and group SDssim_ttest_glm =function(n =200, GR =1, lambda1 =1, M_diff =0) { n1 =round(n / (GR +1)) n2 =round(n1 * GR) lambda2 = lambda1 + M_diff g1 =rpois(n = n1, lambda = lambda1) g2 =rpois(n = n2, lambda = lambda2) Welch =t.test(g1, g2)$p.value GLM =glm(outcome ~ group,data =data.frame(outcome =c(g1, g2),group =c(rep("g1", n1), rep("g2", n2))),family = poisson) res =lst(Welch, GLM =coef(summary(GLM))[2, 4])return(res)}sim_ttest_glm(n =100, M_diff =0.3)
$Welch
[1] 0.6844947
$GLM
[1] 0.6573568
Conditions: First try
# It makes sense to vary group size ratio, lambda, and M_diff# The positive relationship between n and power is trivialconditions =expand_grid(GR =c(0.5, 1, 2), n =200,lambda1 =c(1, 10, 20),M_diff =c(0.3, 0.5, 0.8)) %>%rowid_to_column(var ="condition")conditions
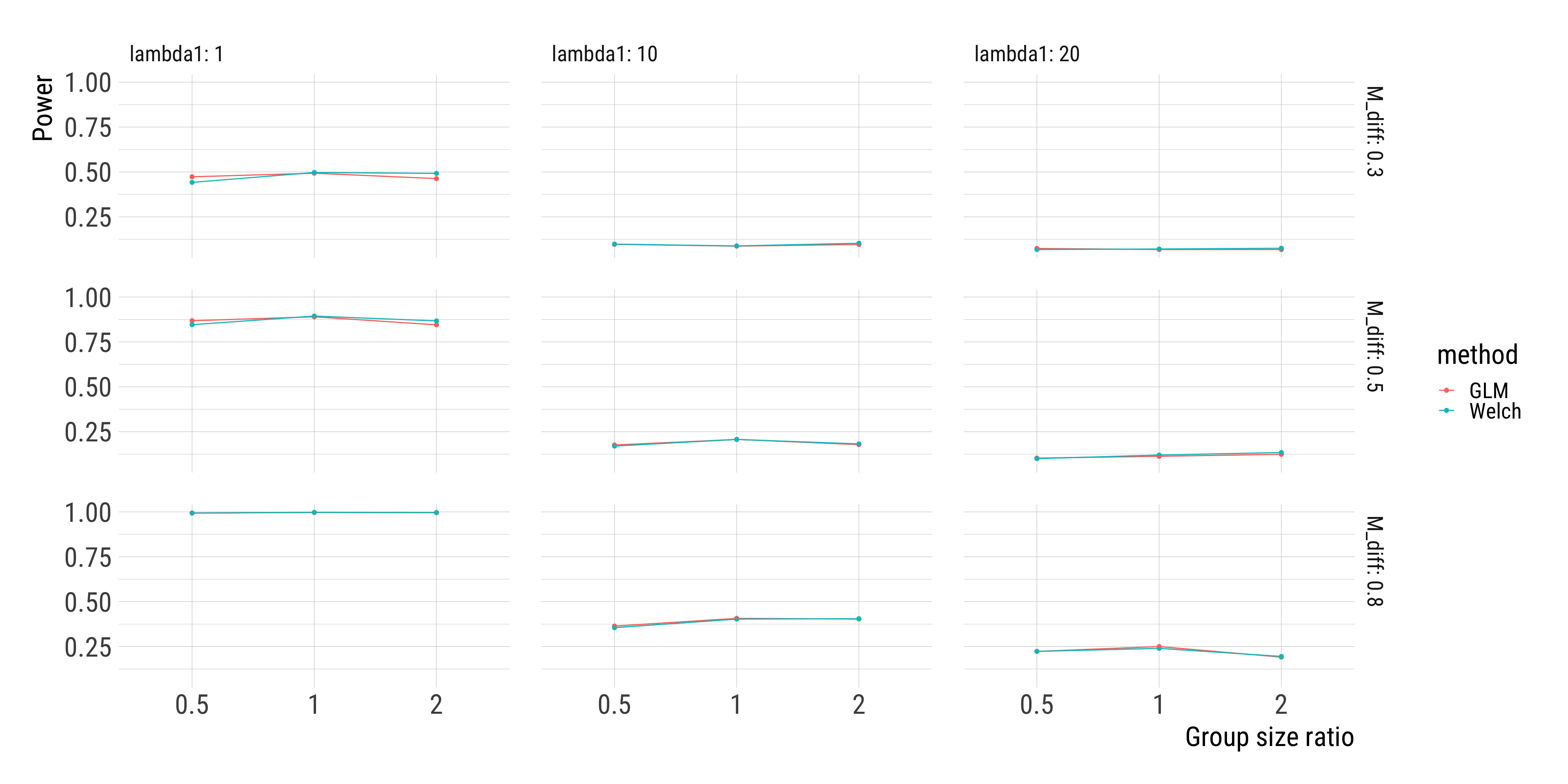
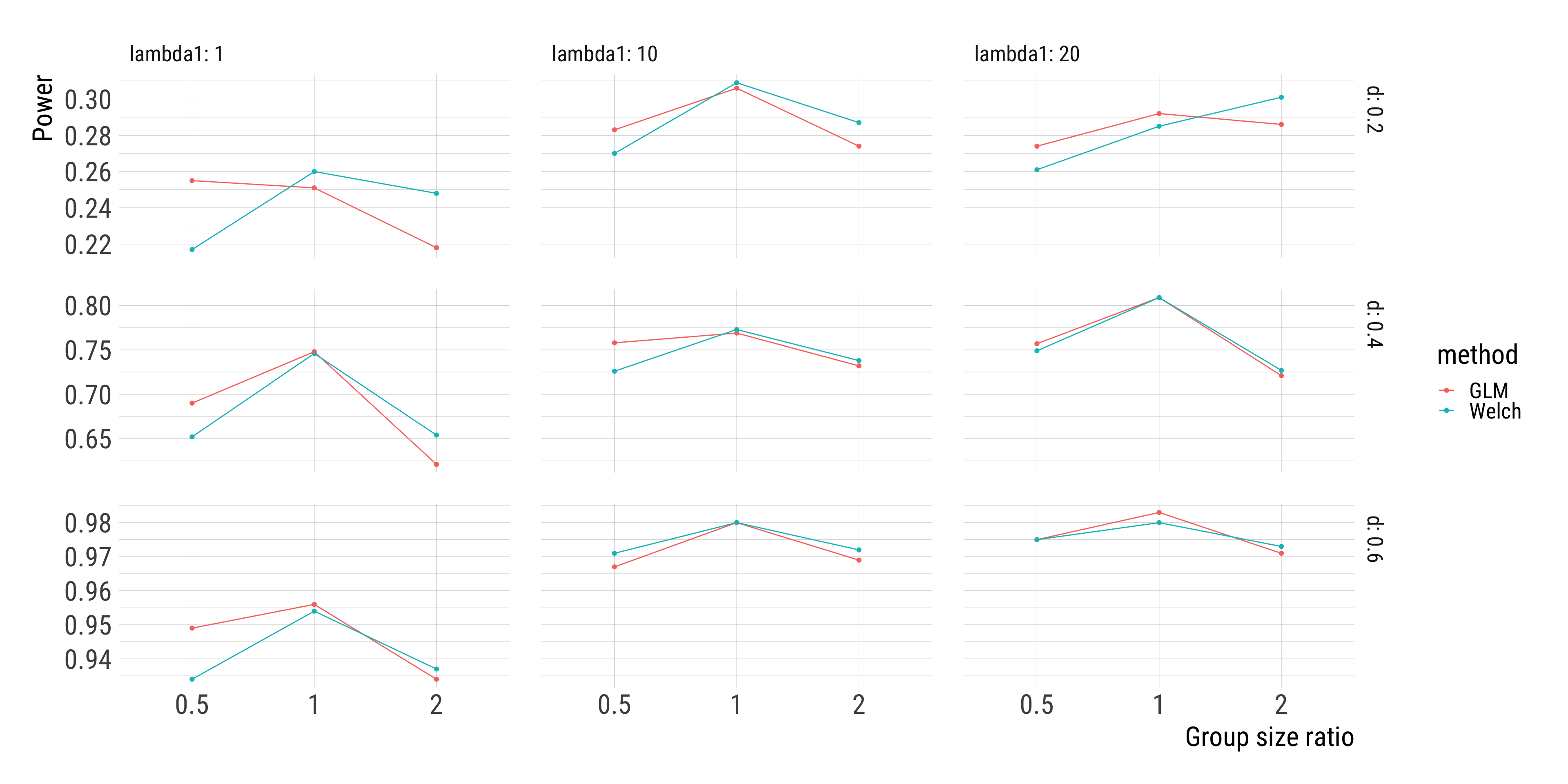
Welch’s t-test and Poisson regression perform very similarly in terms of statistical power.
If the only goal is to compare some group means, the simpler t-test (or a linear model with heteroskedasticity-consistent standard errors) might be good enough.