set.seed(28)
pop_dist = c(0.55, 0.3, 0.1, 0.05)
k = length(pop_dist) # number of categories
categories = LETTERS[1:k] # names of the categories
names(pop_dist) = categories
pop_dist A B C D
0.55 0.30 0.10 0.05 Data Simulation with Monte Carlo Methods
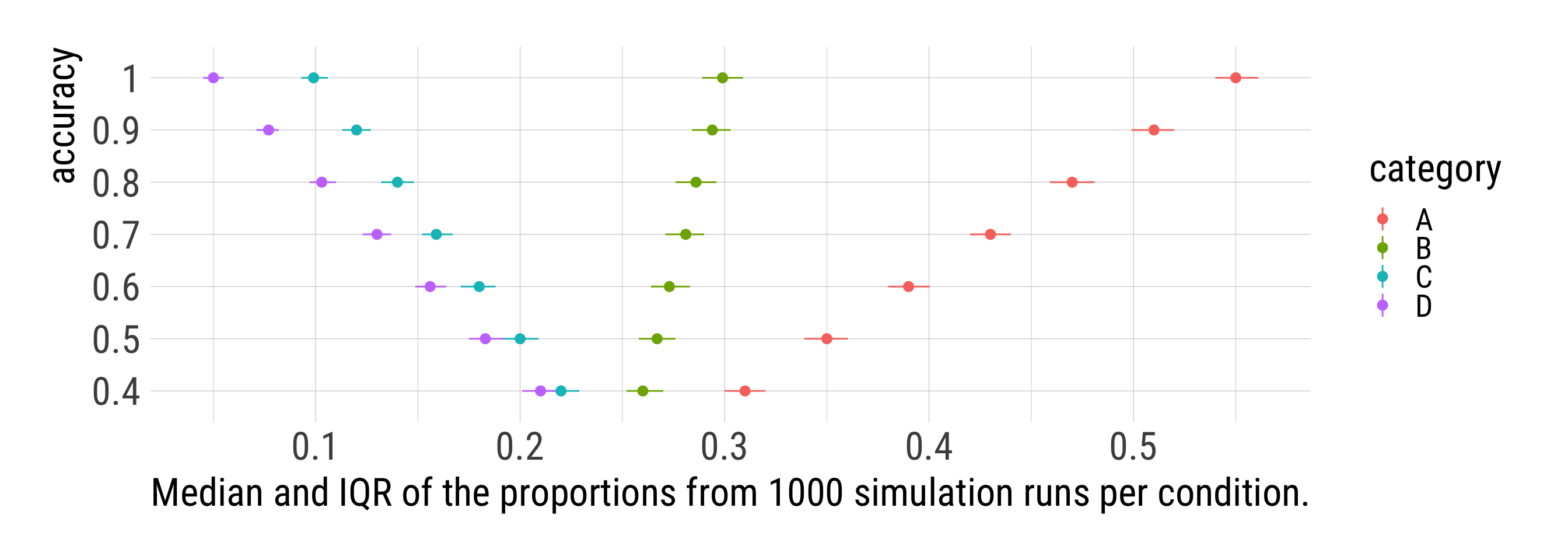
sims %>%
ungroup() %>%
unnest_wider(res) %>%
unnest_longer(freq_obs, indices_to = "category") %>%
group_by(accuracy, category) %>%
summarise(Q = list(quantile(freq_obs, probs = c(0.25, 0.5, 0.75)))) %>%
unnest_wider(Q) %>%
ggplot(aes(`50%`, factor(accuracy),
xmin = `25%`, xmax = `75%`, color = category)) +
geom_pointrange() +
labs(x = str_glue("Median and IQR of the proportions from {i} simulation runs per condition."),
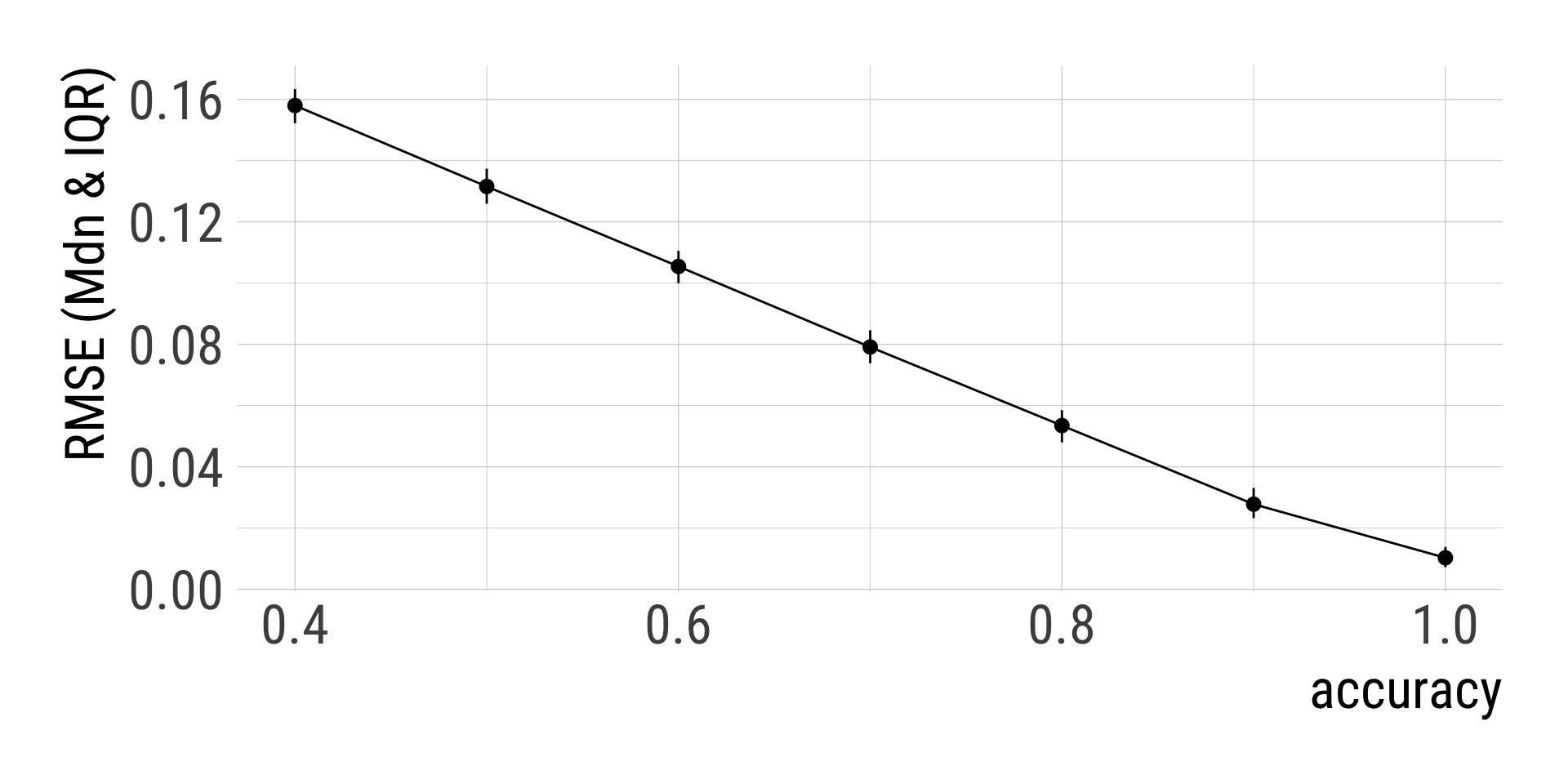
y = "accuracy")sims %>%
ungroup() %>%
unnest_wider(res) %>%
group_by(accuracy) %>%
summarise(Q = list(quantile(rmse, probs = c(0.25, 0.5, 0.75)))) %>%
unnest_wider(Q) %>%
ggplot(aes(accuracy, `50%`, ymin = `25%`, ymax = `75%`)) +
geom_pointrange() +
geom_line() +
labs(y = "RMSE (Mdn & IQR)",
x = "accuracy")n) distribution.sims %>%
ungroup() %>%
unnest_wider(res) %>%
mutate(chi2_pop_dist = map_dbl(pop_dist, ~ chisq.test(.x*100)$statistic)) %>%
ggplot(aes(chi2_pop_dist)) +
geom_histogram()
sims %>%
ungroup() %>%
unnest_wider(res) %>%
mutate(chi2_pop_dist = map_dbl(pop_dist, ~ chisq.test(.x*100)$statistic)) %>%
ggplot(aes(chi2_pop_dist, rmse, color = factor(accuracy))) +
geom_smooth() +
xlim(0, 155) +
labs(x = "chi2_pop_dist",
color = "accuracy",
y = "RMSE",
caption = "method = 'gam' and formula 'y ~ s(x, bs = 'cs')")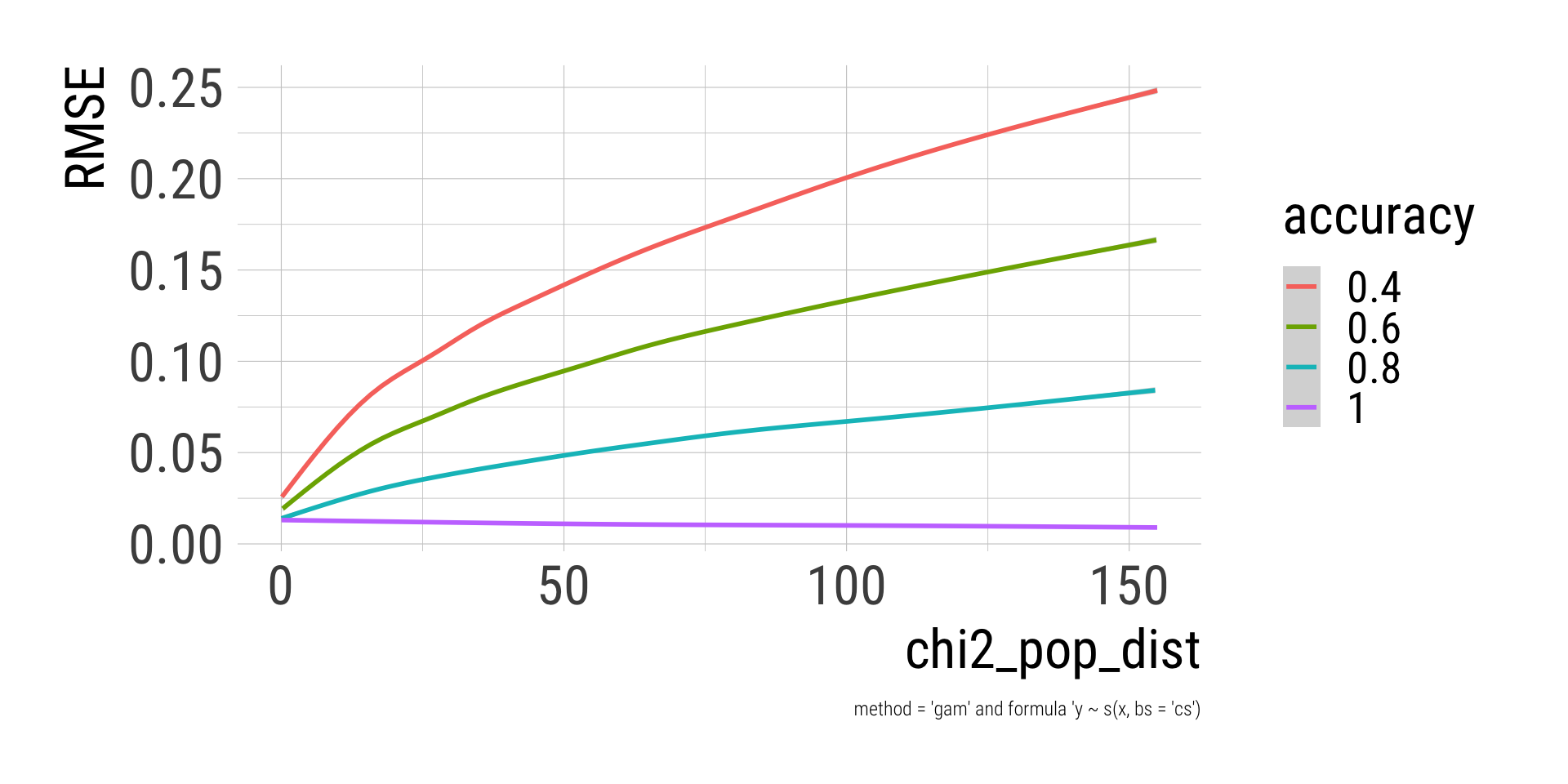
sims %>%
ungroup() %>%
unnest_wider(res) %>%
mutate(chi2_pop_dist = map_dbl(pop_dist, ~ chisq.test(.x*100)$statistic)) %>%
filter(round(chi2_pop_dist) %in% c(0, 25, 50, 75, 100, 125, 150)) %>%
group_by(round(chi2_pop_dist)) %>%
slice(1) %>%
ungroup() %>%
arrange(chi2_pop_dist) %>%
select(chi2_pop_dist, pop_dist) %>%
mutate(pop_dist = map(pop_dist, sort, decreasing = TRUE)) %>%
unnest_wider(pop_dist) %>%
kable(digits = 2, col.names = c("chi2_pop_dist", LETTERS[1:4]))| chi2_pop_dist | A | B | C | D |
|---|---|---|---|---|
| 0.11 | 0.26 | 0.26 | 0.25 | 0.24 |
| 24.58 | 0.40 | 0.34 | 0.14 | 0.12 |
| 50.27 | 0.53 | 0.25 | 0.15 | 0.06 |
| 74.82 | 0.62 | 0.17 | 0.12 | 0.09 |
| 99.68 | 0.68 | 0.16 | 0.10 | 0.06 |
| 124.52 | 0.73 | 0.13 | 0.07 | 0.06 |
| 150.11 | 0.77 | 0.16 | 0.04 | 0.03 |
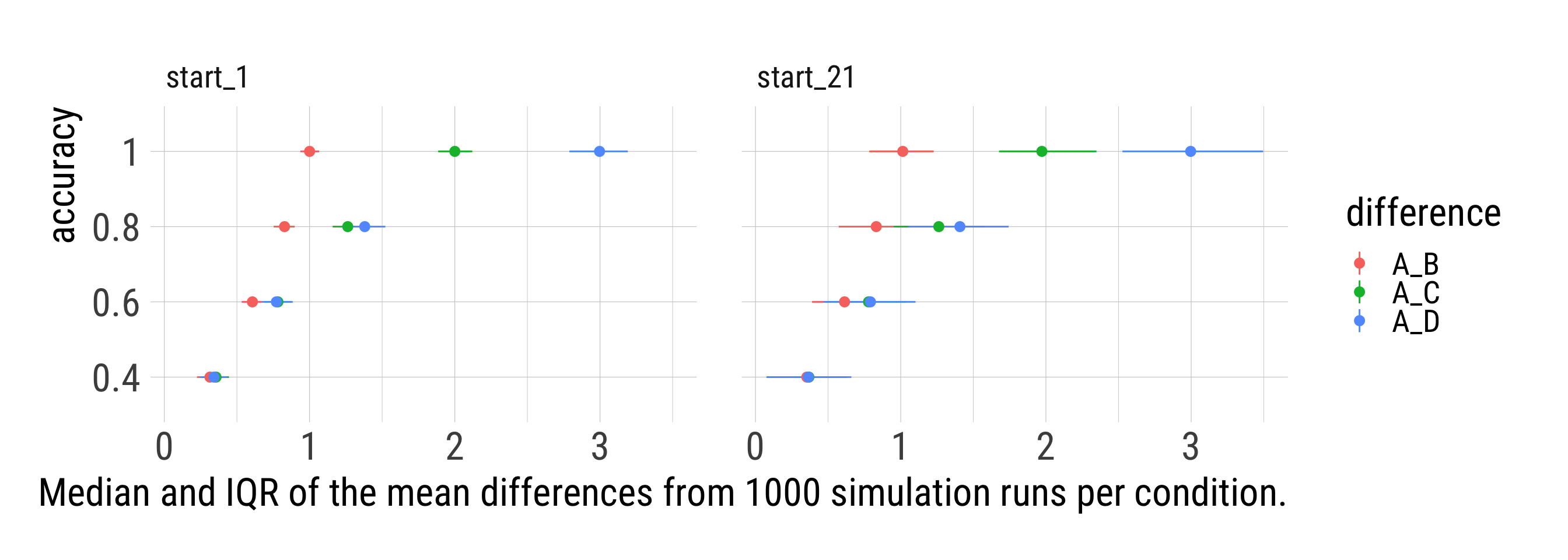
sims %>%
ungroup() %>%
unnest_wider(res) %>%
unnest_longer(diff_obs, indices_to = "difference") %>%
mutate(lambdas = names(lambdas)) %>%
group_by(accuracy, difference, lambdas) %>%
summarise(Q = list(quantile(diff_obs, probs = c(0.25, 0.5, 0.75)))) %>%
unnest_wider(Q) %>%
ggplot(aes(`50%`, factor(accuracy),
xmin = `25%`, xmax = `75%`, color = difference)) +
geom_pointrange() +
facet_wrap(vars(lambdas)) +
labs(y = "accuracy",
x = str_glue("Median and IQR of the mean differences from {i} simulation runs per condition."))sims %>%
ungroup() %>%
unnest_wider(res) %>%
unnest_longer(diff_obs, indices_to = "difference") %>%
mutate(
diff_true = case_when(
difference == "A_B" ~ 1L,
difference == "A_C" ~ 2L,
difference == "A_D" ~ 3L
),
recovered = diff_obs / diff_true,
lambdas = names(lambdas)
) %>%
select(accuracy, difference, lambdas, diff_obs, diff_true, recovered) %>%
group_by(accuracy, difference, lambdas) %>%
summarise(Q = list(quantile(recovered, probs = c(0.25, 0.5, 0.75)))) %>%
unnest_wider(Q) %>%
ggplot(aes(`50%`, factor(accuracy),
xmin = `25%`, xmax = `75%`, color = difference)) +
geom_pointrange() +
facet_wrap(vars(lambdas)) +
labs(y = "accuracy",
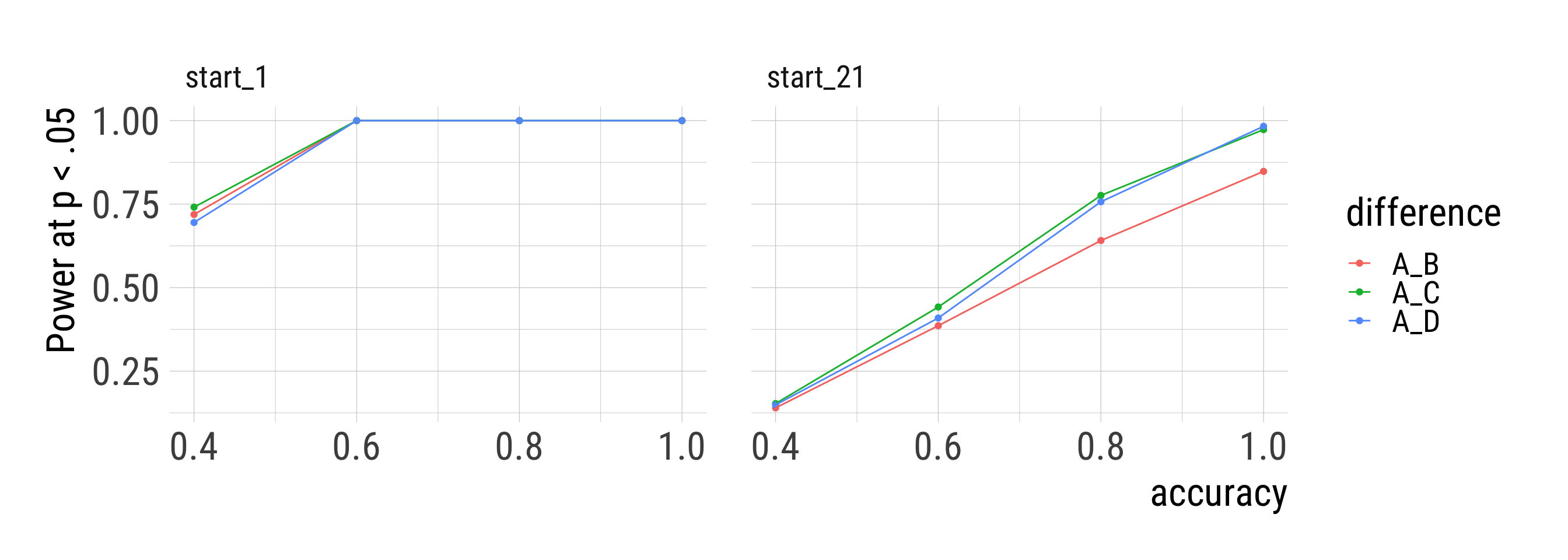
x = str_glue("Median and IQR of the ratio true by observed difference\nfrom {i} simulation runs per condition."))sims %>%
ungroup() %>%
mutate(lambdas = names(lambdas)) %>%
unnest_wider(res) %>%
unnest_longer(p_obs, indices_to = "difference") %>%
group_by(accuracy, difference, lambdas) %>%
summarise(P_p05 = mean(p_obs < 0.05)) %>%
ggplot(aes(accuracy, P_p05, color = difference)) +
geom_point() + geom_line() +
facet_wrap(vars(lambdas)) +
labs(y = "Power at p < .05")