misclass_prob = matrix(c(
.80, .10, .15,
.15, .80, .15,
.05, .10, .70
), nrow = 3, byrow = TRUE,
dimnames = list(LETTERS[1:3], LETTERS[1:3]))
misclass_prob A B C
A 0.80 0.1 0.15
B 0.15 0.8 0.15
C 0.05 0.1 0.70Data Simulation with Monte Carlo Methods
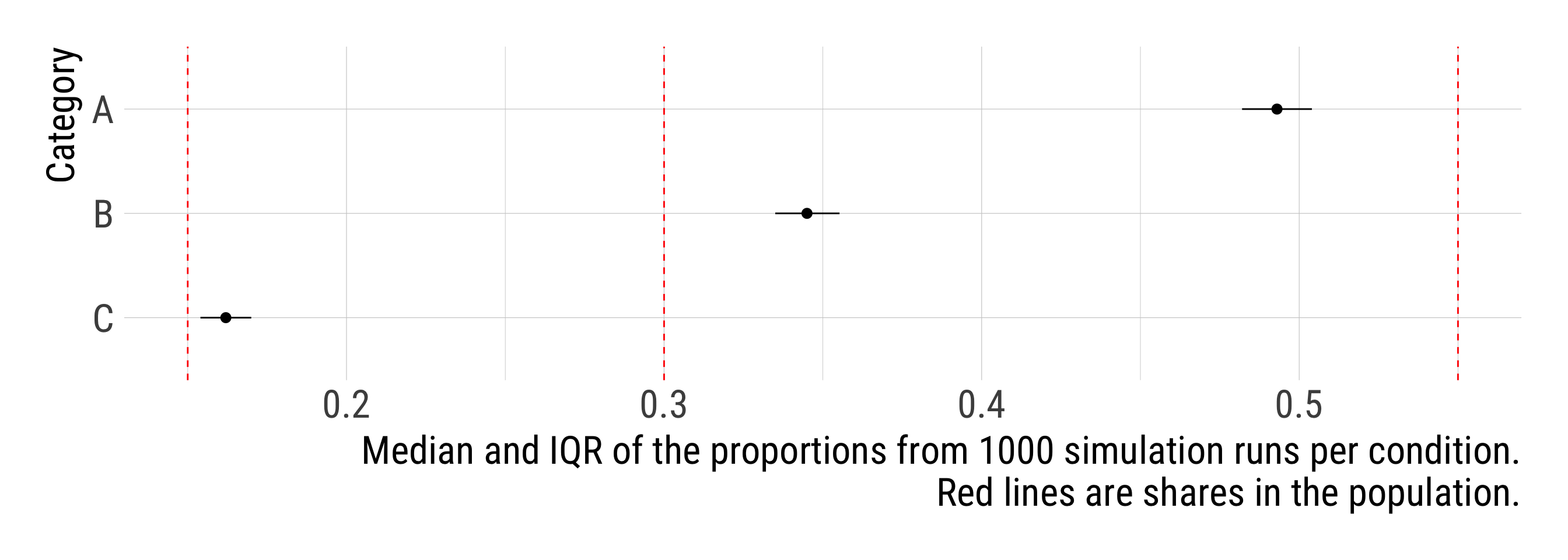
sims %>%
ungroup() %>%
unnest_wider(res) %>%
unnest_longer(freq_obs, indices_to = "category") %>%
group_by(category) %>%
summarise(Q = list(quantile(freq_obs, probs = c(0.25, 0.5, 0.75)))) %>%
unnest_wider(Q) %>%
ggplot(aes(`50%`, fct_rev(category),
xmin = `25%`, xmax = `75%`)) +
geom_pointrange() +
geom_vline(xintercept = unlist(conditions$pop_dist), color = "red", linetype = 2) +
labs(x = str_glue("Median and IQR of the proportions from {i} simulation runs per condition.\nRed lines are shares in the population."),
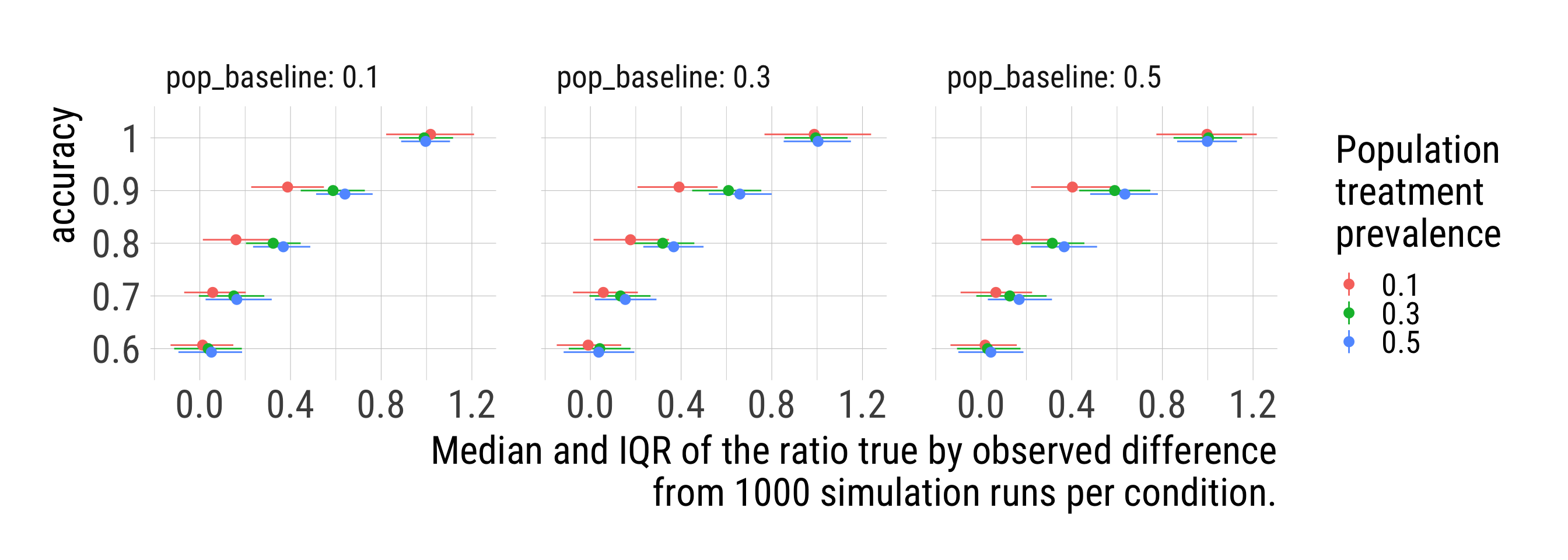
y = "Category")sims %>%
ungroup() %>%
unnest_wider(res) %>%
group_by(accuracy, pop_baseline, pop_dist_x) %>%
summarise(Q = list(quantile(diff_obs_rel, probs = c(0.25, 0.5, 0.75)))) %>%
unnest_wider(Q) %>%
ggplot(aes(`50%`, factor(accuracy), color = factor(pop_dist_x),
xmin = `25%`, xmax = `75%`)) +
geom_pointrange(position = position_dodge(width = -.2)) +
facet_wrap(vars(pop_baseline), labeller = "label_both") +
labs(y = "accuracy",
x = str_glue("Median and IQR of the ratio true by observed difference\nfrom {i} simulation runs per condition."),
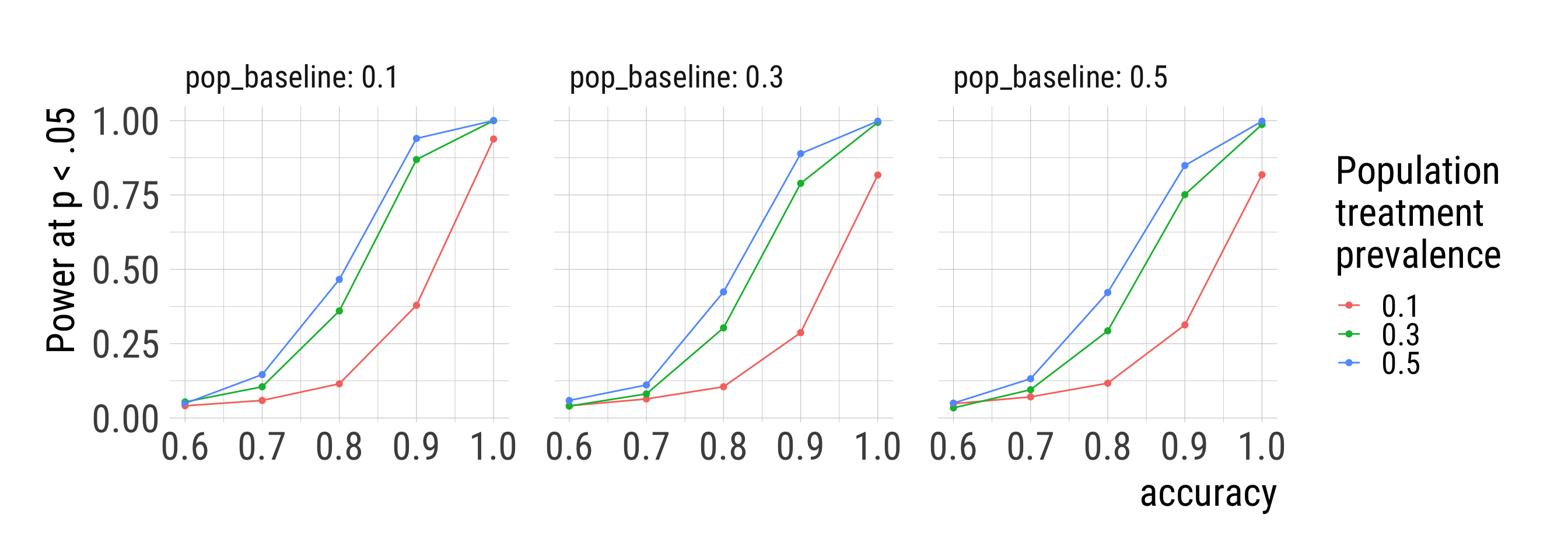
color = "Population\ntreatment\nprevalence")sims %>%
ungroup() %>%
unnest_wider(res) %>%
group_by(accuracy, pop_baseline, pop_dist_x) %>%
summarise(P_p05 = mean(p_obs < 0.05)) %>%
ggplot(aes(accuracy, P_p05, color = factor(pop_dist_x))) +
geom_point() + geom_line() +
facet_wrap(vars(pop_baseline), labeller = "label_both") +
labs(y = "Power at p < .05", color = "Population\ntreatment\nprevalence")