Section 6 Model estimation, comparison, and selection
6.1 Model estimation
We fitted the topic models with the recommended prior settings and initialization (Roberts, Stewart, and Tingley 2019). We also estimated the change in topic prevalences over time and differences between the platforms. The model specification is documented below, where impf_stm is the document-term matrix in the format of the stm package (object out in Section 5) and K is the number of topics.
stm(impf_stm$documents, impf_stm$vocab, data = impf_stm$meta, prevalence = ~s(date_num,
degree = 2) + platform, init.type = "Spectral", K = K)In total, we estimated 18 models with 10 to 70 topics. The subsequent code loads the fitted models or, if the file does not exist, estimates them from the replication data. Note that the estimation of all 18 models may take a few hours and will consume considerable computing resources.
library(stm)
library(furrr)
library(tidyverse)
theme_set(theme_bw())
# Load replication data: document-feature matrix
load("R/data/replication_data.rdata")
# Load fitted models or fit models Note that this may take a long time and
# requires plenty of RAM and CPU ressources!
if (file.exists("R/data/fitted_stm.rdata")) {
load("R/data/fitted_stm.rdata")
topic_models = ls()[startsWith(ls(), "stm")] %>% map(~eval(expr = as.name(.x),
envir = .GlobalEnv))
many_models = tibble(K = sort(c(seq.int(10, 70, length.out = 7), 31:39,
45, 55)), topic_model = topic_models)
rm(list = ls()[startsWith(ls(), "stm")])
rm(topic_models)
} else {
# Fit models in parallel K is the number of topics
plan(multiprocess(workers = 7))
many_models = tibble(K = sort(c(seq.int(10, 70, length.out = 7), 31:39,
45, 55))) %>% mutate(topic_model = future_map(K, ~stm(out$documents,
out$vocab, data = out$meta, prevalence = ~s(date_num, degree = 2) +
platform, init.type = "Spectral", K = ., verbose = FALSE), .progress = TRUE),
est = future_map2(K, topic_model, ~estimateEffect(as.formula(paste0("1:",
.x, " ~ s(date_num, degree = 2) + platform")), .y, out$meta), .progress = TRUE))
plan(sequential)
}6.2 Model comparison
We compared the models by four quantitative measures: held-out likelihood, multinomial dispersion of the residuals, semantic coherence, and exclusivity.
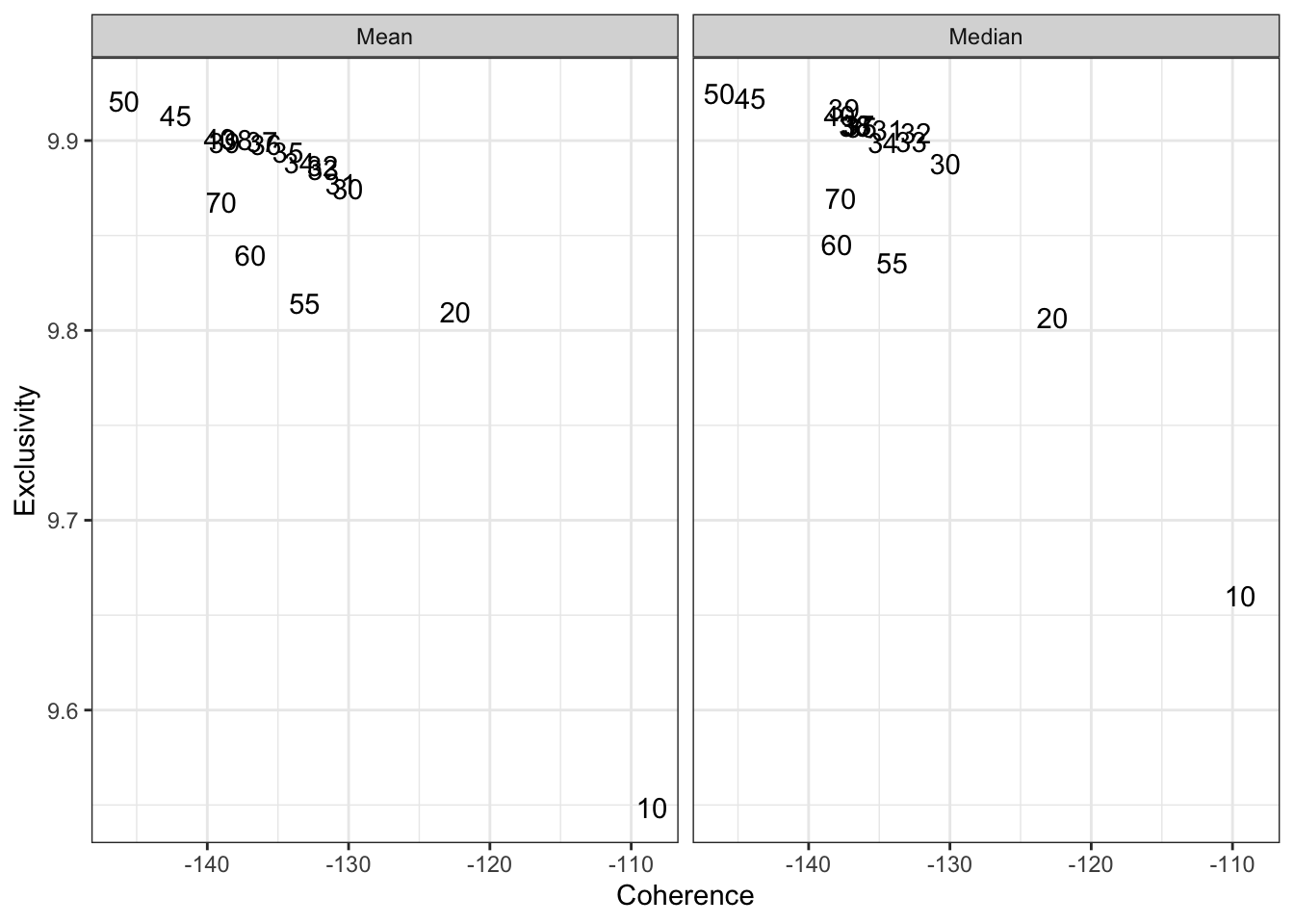
Figure 6.1: Exclusivity and semantic coherence by number of topics
Figure 6.1 presents the semantic coherence on the x axis and the exclusivity on the y axis. Both measures are characteristics of the topics. They were summarized across all topic in a model by taking the mean (left facet) and the median (right facet). The numbers in the plot refer to the number of topics of a model. Higher semantic coherence indicates a higher probability that the most typical terms for a topic co-occur in texts with the same topic (Mimno et al. 2011). Higher exclusivity indicates that the most typical terms for one topic are less likely to occur in the most typical terms of other topics (Roberts et al. 2014). The absolute values of both metrics have no substantial meaning. They must be compared across the candidate models. An adequate model will balance both semantic coherence (i.e., the typical terms of a topic are likely to appear together in a text) and exclusivity (i.e., the typical terms of one topic will not be typical for other topics). Figure 6.1 shows that for models from 10 to 50 topics, the exclusivity increased at the expense of the coherence. The models with 55 or more topics were less exclusive than the model with 50 topics, indicating substantial overlap between some topics. The topics of the models with 10 and 20 topics had high coherence, but lacked exclusivity. We identified the models in the range of 30 to 40 models as the most promising candidate models according to these metrics.
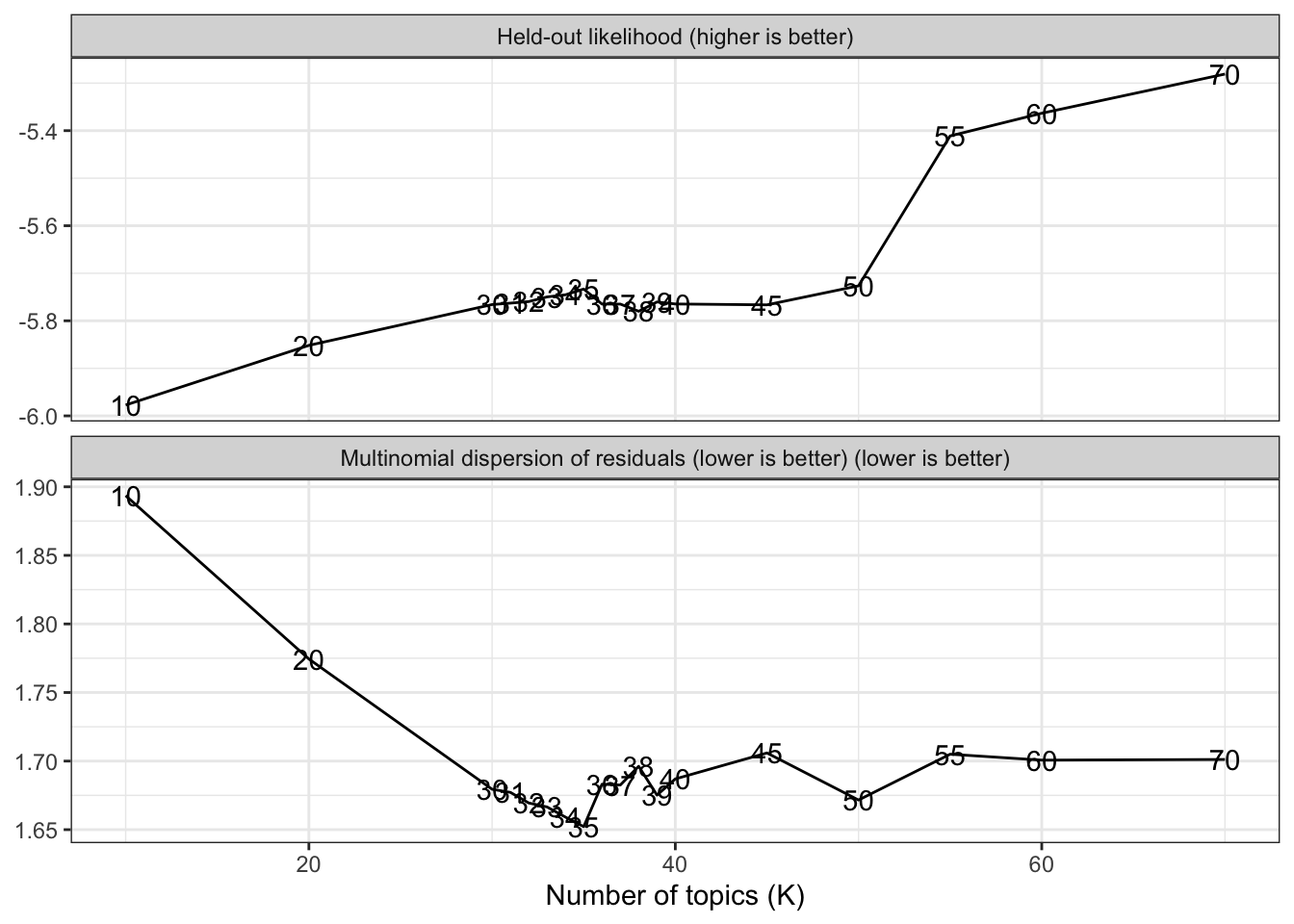
Figure 6.2: Held-out likelihood and multinomial dispersion of residuals by number of topics
The first plot in Figure 6.2 shows the held-out likelihood as a function of the number of topics. The held-out likelihood measures the performance of a model on a prediction task with a held-out sample. Some words are removed from the documents. The model is trained on the data and is then used to predict the probablity that the removed words appeared in the documents. Higher values indicate better model fit. The models with at least 55 topics performed best. No meaningful difference existed within the 30 to 50 topics range. The second facet of Figure 6.2 presents the multinomial dispersion of the residuals, where lower values indicate better model fit. The model with 35 topics came in first, but all models between 30 and 70 topics performed similarly well.
All models with between 30 and 40 topics were inspected by the researchers using qualitative content analysis (Mayring 2014). We used the most typical terms and posts to identify the substantial meanings of the topics (see also Section 9). The model with 35 topics was judged the most appropriate compromise between general topics and informative details, and it also showed good quantitative model fit.
References
Mayring, Philipp. 2014. Qualitative Content Analysis: Theoretical Foundation, Basic Procedures and Software Solution.
Mimno, David, Hanna M. Wallach, Edmund Talley, Miriam Leenders, and Andrew McCallum. 2011. “Optimizing Semantic Coherence in Topic Models.” Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, 262–72.
Roberts, Margaret E., Brandon M. Stewart, and Dustin Tingley. 2019. “Stm: An R Package for Structural Topic Models.” Journal of Statistical Software 91 (1): 1–40. https://doi.org/10.18637/jss.v091.i02.
Roberts, Margaret E., Brandon M. Stewart, Dustin Tingley, Christopher Lucas, Jetson Leder-Luis, Shana Kushner Gadarian, Bethany Albertson, and David G. Rand. 2014. “Structural Topic Models for Open-Ended Survey Responses.” American Journal of Political Science 58 (4): 1064–82. https://doi.org/10.1111/ajps.12103.